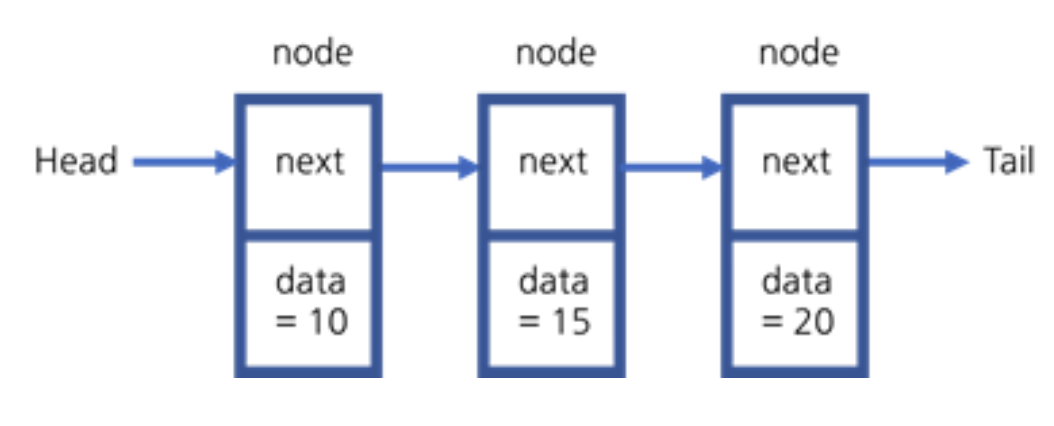
각각의 노드들은 다음 노드를 가리키는 포인터, 자신의 값을 가지고 있는 데이터를 가리키는 포인터 2개로 구성
마지막 노드의 다음 노드는 없으므로 null을 가리키게 된다.
head라는 포인터는 첫번째 노드의 주소를 가지고 있다.
힙에서는 연결 리스트의 head만 알고 있기 때문에 head.next를 이용하여 연결리스트를 탐색한다.
1.1 배열과 비교
배열
논리적 저장 순서와 물리적 저장 순서가 일치
찾고자 하는 원소의 인덱스를 알고 있으면 O(1)으로 원소에 접근 가능 → Random Access 가능
삭제와 삽입시 빈 공간이 생겨 shift를 해줘야 함 → 비용 : O(n)
연결 리스트
각각의 노드는 다음 노드를 알고 있으므로 원소를 추가나 삭제할 때 비용이 배열보다 덜 든다.(O(1))
논리적 저장 순서와 물리적 저장 순서가 일치 하지 않기 때문에 원하는 위치를 찾으려면 첫 노드부터 탐색해야 한다. → 비용 : O(n)
트리 구조의 근간이 됨.
2. 구현
public class LinkedList<E> implements List{
private static class Node<E> { //노드 정의
E data;
Node<E> next;
public Node(E obj) {
data = obj;
next = null;
}
}
private Node<E> head;
private int currentSize;
public LinkedList() {
head = null;
currentSize = 0;
}
}
노드로 현재 데이터와 뒤의 위치를 표시한다.
링크드 리스트는 맨 앞부터 탐색하여 뒤의 있는 데이터까지 탐색하여 나가기 때문에 head가 필요하다.
2.1 addFirst()
새로운 노드가 헤드를 가리키게 만든다.
헤드를 새로운 노드로 바꾼다.
결국 새로운 노드가 앞에 삽입된다.
시간 복잡도: O(n)
public void addFirst(E obj) {
Node<E> newNode = new Node<>(obj);
newNode.next = head;
head = newNode;
currentSize++;
}
2.2 addLast()
시간복잡도: O(n)
public void addLast(E obj) {
Node<E> newNode = new Node<>(obj);
//경계 조건
if (head == null) {
head = newNode;
currentSize++;
return;
}
Node<E> temp = head;
while (temp.next != null) {
temp = temp.next;
}
temp.next = newNode;
currentSize++;
}
시간복잡도: O(1) (tail(링크드 리스트의 마지막을 나타내는 노드)을 구현했을 경우)
public void addLast(E obj) {
Node<E> newNode = new Node<>(obj);
if (head == null) {
head = newNode;
tail = newNode;
currentSize++;
return;
}
tail.next = newNode;
tail = newNode;
currentSize++;
}
2.3 removeFirst()
public E removeFirst() {
//리스트가 비어있을 경우
if (head == null) {
return null;
}
E temp = head.data;
//리스트의 요소가 1개일 경우
if (head == tail) {
head = null;
tail = null;
} else {
head = head.next;
}
currentSize--;
return temp;
}
2.4 removeLast()
public E removeLast() {
//리스트가 비어 있을 때
if (head == null) {
return null;
}
//리스트의 요소가 1개일 때
if (head == tail) {
return removeFirst();
}
//나머지 경우
Node<E> current = head;
Node<E> previous = null;
while (current != tail) {
previous = current;
current = current.next;
}
previous.next = null;
tail = previous;
currentSize--;
return current.data;
}
2.5 remove()
public E remove(E obj) {
Node<E> previous = null;
Node<E> current = head;
//비교
while (current != null) {
if ((((Comparable<E>) obj).compareTo(current.data)) == 0) {
//찾는 원소가 첫번째에 있을 때
if (current == head) {
return removeFirst();
}
//찾는 원소가 마지막에 있을 때
if (current == tail) {
return removeLast();
}
currentSize--;
previous.next = current.next;
return current.data;
}
previous = current;
current = current.next;
}
return null;
}
2.6 contains()
public boolean contains(E obj) {
Node<E> current = head;
//비교하여 값이 같으면 true 반환
while (current != head) {
if ((((Comparable<E>) obj).compareTo(current.data)) == 0) {
return true;
}
current = current.next;
}
//일치하는게 없을 경우 flase 반환
return false;
}
2.7 peekFrist(), peekLast()
링크드리스트의 앞쪽과 맨 뒷쪽을 출력하는 함수
public E peekFirst() {
if (head == null) {
return null;
}
return head.data;
}
public E peekLast() {
if (tail == null) {
return null;
}
return tail.data;
}