
Chapter10 가상메모리 관리
1. Virtual Memory Management
- 가상 메모리 시스템의 성능을 최적화 하는 것
2. Cost Model
- 구성 요소
- Page fault frequency : page fault 발생 빈도
- Page fault rate : page fault 발생률
- 발생률과 발생 빈도를 최소화 시켜야 함. → context switch, kernel 개입을 최소화
- Page reference string (d)
- 프로세스의 수행 중 참조한 페이지 번호 순서
- $\omega = r_1r_2\cdots r_k\cdots r_T$
- $r_i$ = 페이지 번호, $r_i\in {0,1,2,\cdots,N-1}$
- N : 프로세스의 페이지 수
- $\omega = r_1r_2\cdots r_k\cdots r_T$
- 프로세스의 수행 중 참조한 페이지 번호 순서
- Page fault rate = F($\omega$)
- $F(\omega)=\frac{Num.of,page,faults,during,\omega}{|w|}$
3. Hardware Components
- Address translation device (주소 사상 장치)
- 주소의 사상을 효율적으로 수행하기 위해 사용
- ex) TLB, Cache memories
- Bit vectores
- page 사용 상황에 대한 정보를 기록하는 비트들
- 주로 배열처럼 묶어서 사용
- Referece bits (used bits)
- 메모리에 적재된 각각의 page가 최근에 참조 되었는지 확인
- 주기적으로 0으로 초기화하고 참조가 되면 1로 설정
- Update bits (dirty bits)
- Page가 메모리에 적재된 후, 프로세스에 의해 수정 되었는지 확인
- 주기적 초기화는 없음
- update bit = 1이면 main memory상의 내용이 swap device상의 내용과 다른것을 의미 → 즉, write-back이 필요
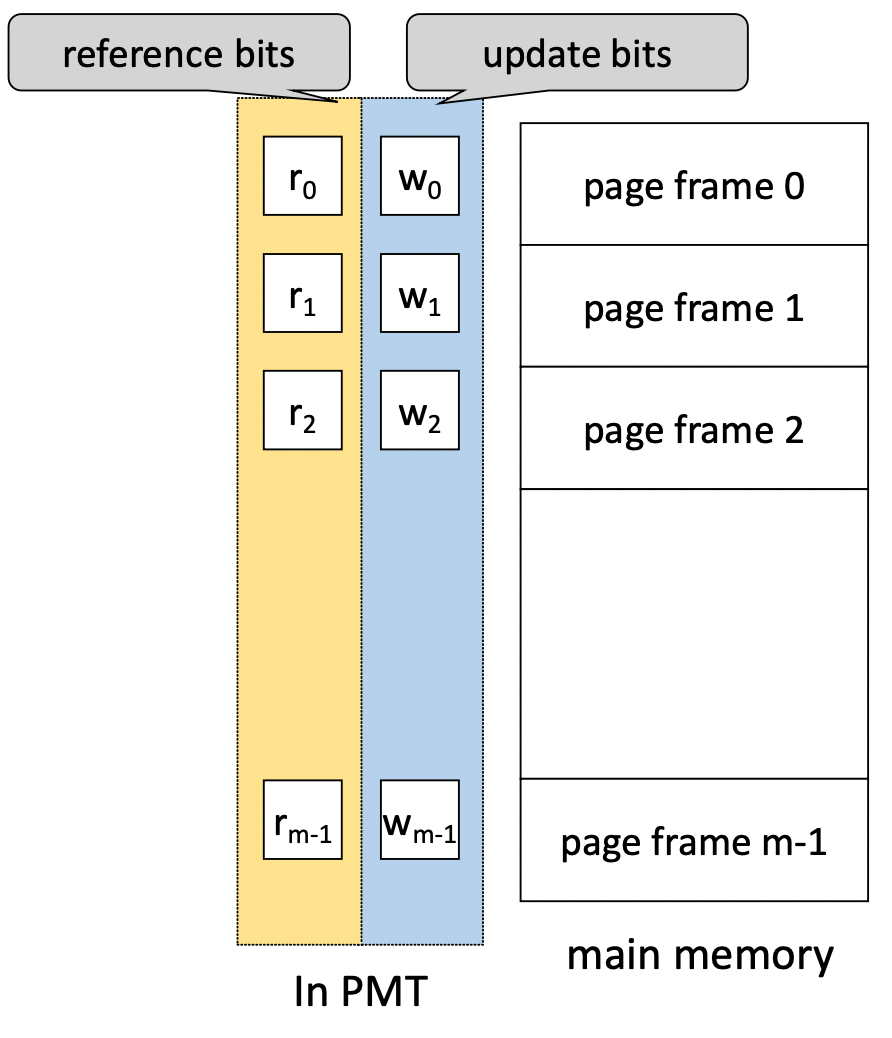
- page 사용 상황에 대한 정보를 기록하는 비트들
4. Software Components
4.1 Allocations strategies(할당 기법)
- 각 프로세스에게 메모리를 얼마 만큼 줄 것인가?
- Fixed allocation(고정 할당) : 프로세스의 실행 동안 고정된 크기의 메모리 할당
- Variable allocation(가변 할당) : 프로세스의 실행 동안 할당하는 메모리가 유동적
- 프로세스 실행에 필요한 메모리의 양을 예측해야 함.
- 너무 큰 메모리 할당 → 메모리 낭비
- 너무 작은 메모리 할당 → page fault rate ↑
4.2 Fetch strategies
- 특정 Page를 메모리에 언제 적재할 것인가?
- Demand fetch (demand paging) : 프로세스가 참조하는 페이지만 적재
- Anticipatory fetch (pre-paging) : 참조될 가능이 높은 페이지를 예측하여 적재
- 잘못된 예측 시 자원 낭비가 큼
- 실제 대부분의 시스템은 demand fetch 기법을 사용
4.3 Placement strategies(배치 기법)
- Page/segment를 어디에 적재할 것인가?
- paging system에서는 불필요
4.4 Replacement strategies(교체 기법)
- 새로운 page를 어떤 page와 교체 할 것인가?
- Fixed allocation을 위한 교체 기법
- MIN algorithm
- Random algorithm
- FIFO algorithm
- LRU algorithm
- LFU algorithm
- NUR algorithm
- Clock algorithm
- Second chance algorithm
- Variable allocation을 위한 교체 기법
- VMIN algorithm
- WS algorithm
- PFF algorithm
- → 5번에서 설명
- Fixed allocation을 위한 교체 기법
4.5 Cleaning strategies(정리 기법)
- 변경 된 page를 언제 wirte-back(swap-device에 반영하는 것) 할 것인가?
- Demand cleaning : 해당 page에 메모리에서 내려올 때
- Anticipatory cleaning : 더 이상 변경될 가능성이 없다고 판단 할 때
- 잘못된 예측 시 자원 낭비가 큼
- 실제 대부분의 시스템에서는 Demand cleaning 기법 사용
4.6 Load control stragies(부하 조절 기법)
- 시스템의 multi-programming degree 조절
- 적정 수준으로 유지해야 함 (plateau 상태)
- 저부하 상태 (under-loaded) → 시스템 자원 낭비, 성능 저하
- 고부하 상태 (over-loaded) → Thrashing(스레싱) 현상 : 과도한 page fault 발생
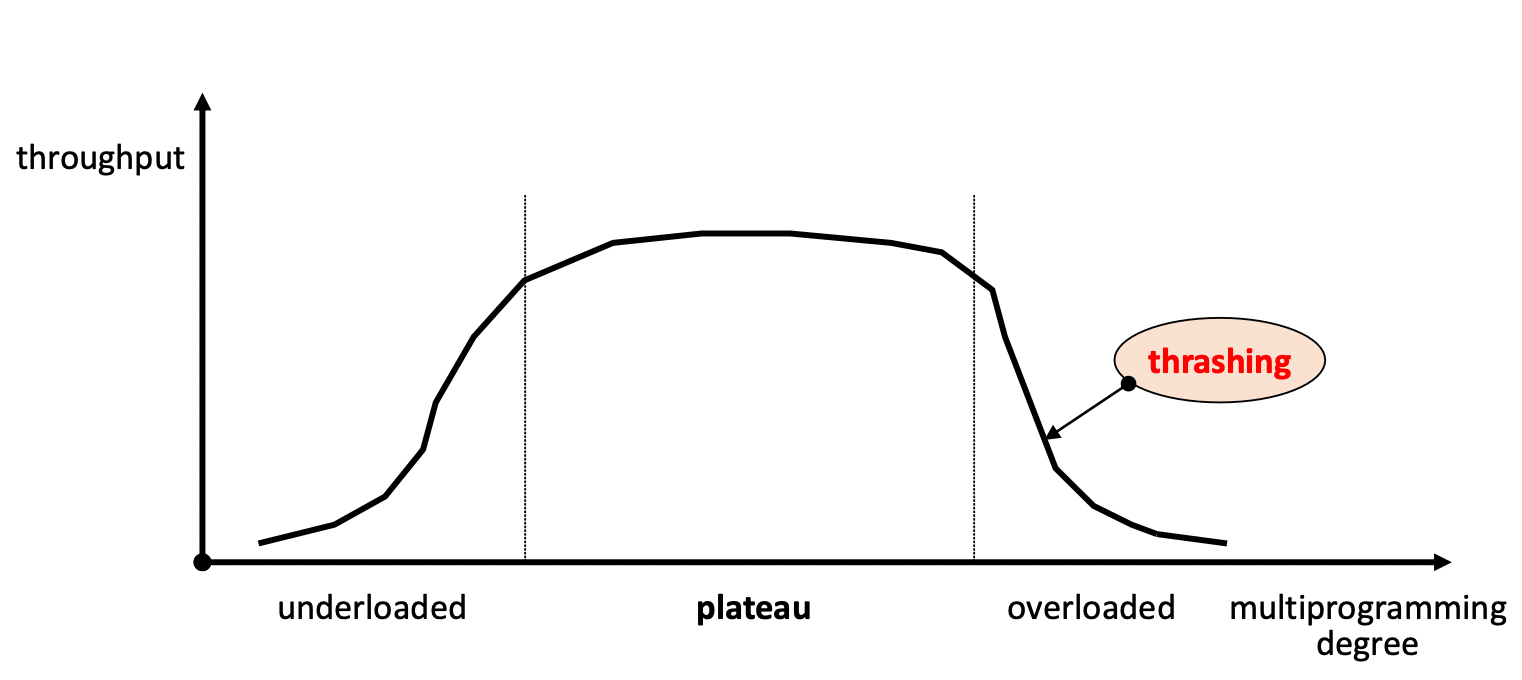
5. Page replacement schemes
- Locality
- 프로세스가 프로그램/데이터의 특정 영역읠 집중적으로 참조하는 현상
- Spatical locality
- Temporal locality
5.1 Fixed allocation을 위한 교체 기법
1. MIN algorithm
- page fault frequency를 최소화 하는 알고리즘
- 앞으로 가장 오랫동안 참조되지 않을 page 교체
- tie-breaking rule : 교체될 page의 순위가 동등하다면 page 번호가 가장 큰/작은 페이지 교체
- 앞으로 가장 오랫동안 참조되지 않을 page 교체
- 실현 불가능한 기법이지만 교체 기법의 성능 평가 도구로 사용
-


2. Random algorithm
- 무작위로 교체할 page 선택
- overhead↓
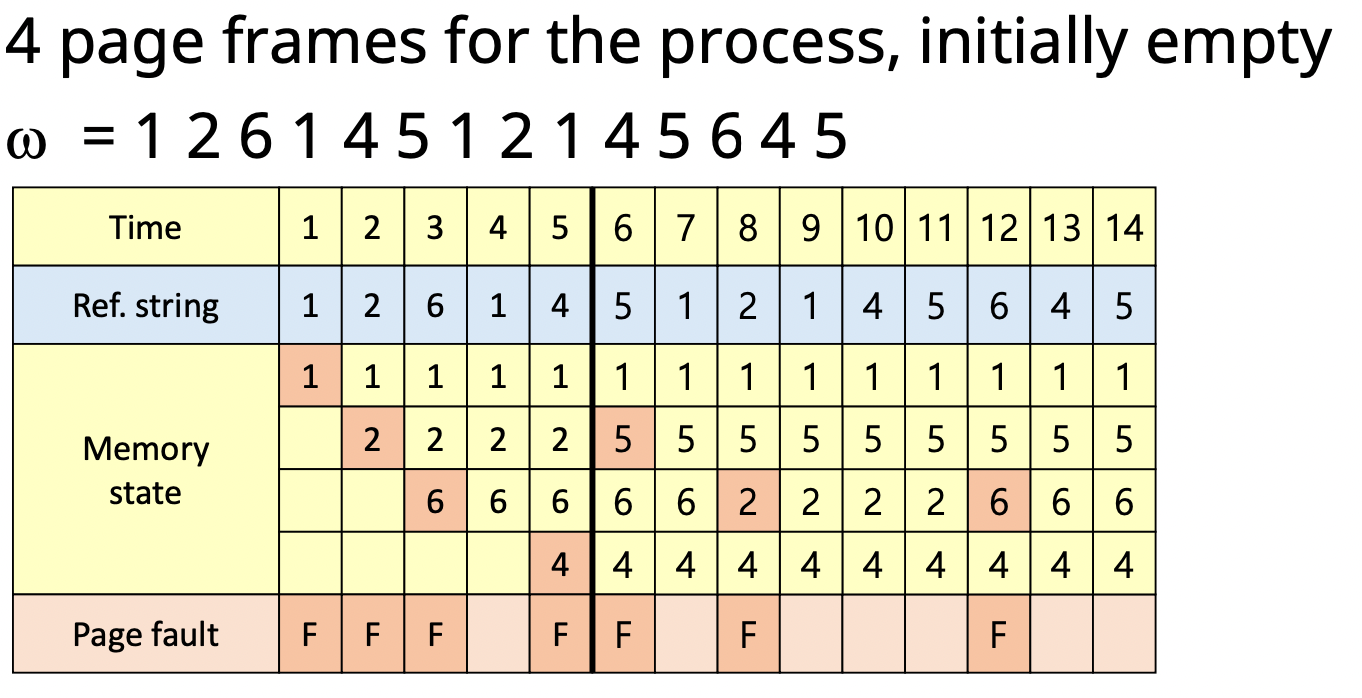
3. FIFO algorithm
- First In First Out : 가장 오래된 page를 교체
- Locality를 고려 안함
- FIFO anomaly : 더 많은 page frame을 할당 하더라도 page fault의 수가 증가하는 경우가 존재
-

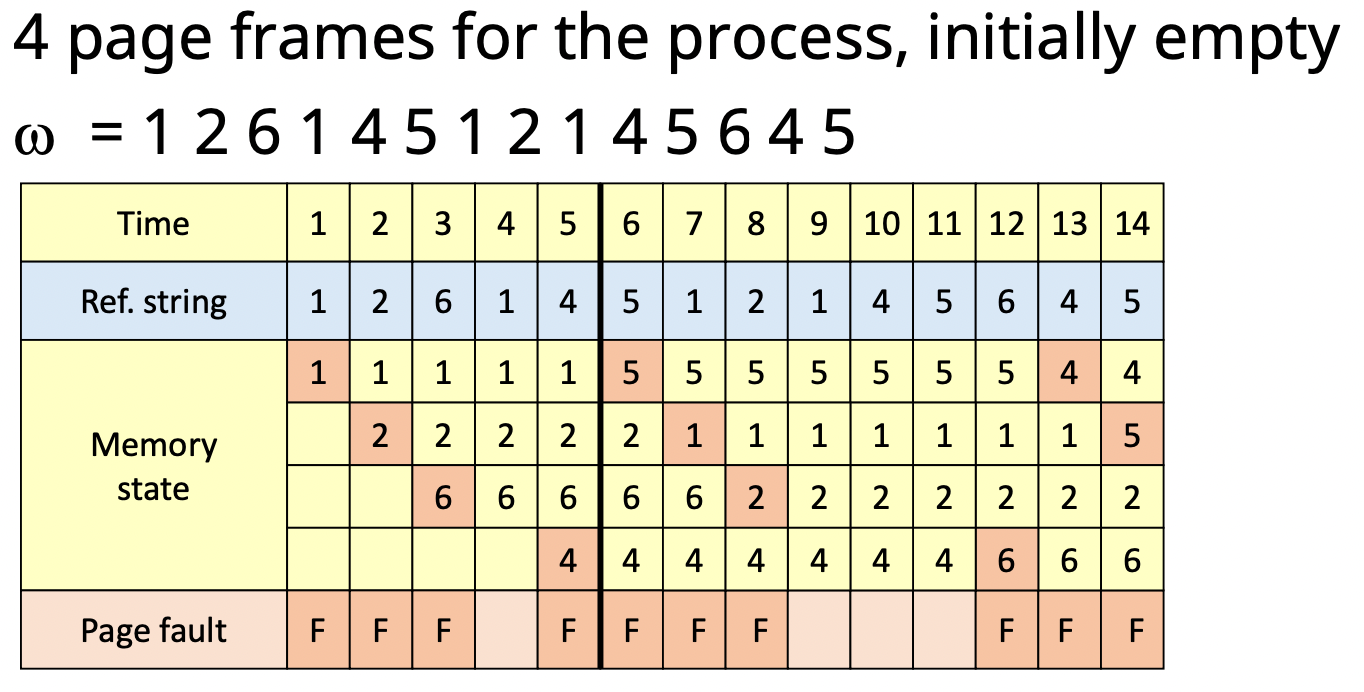
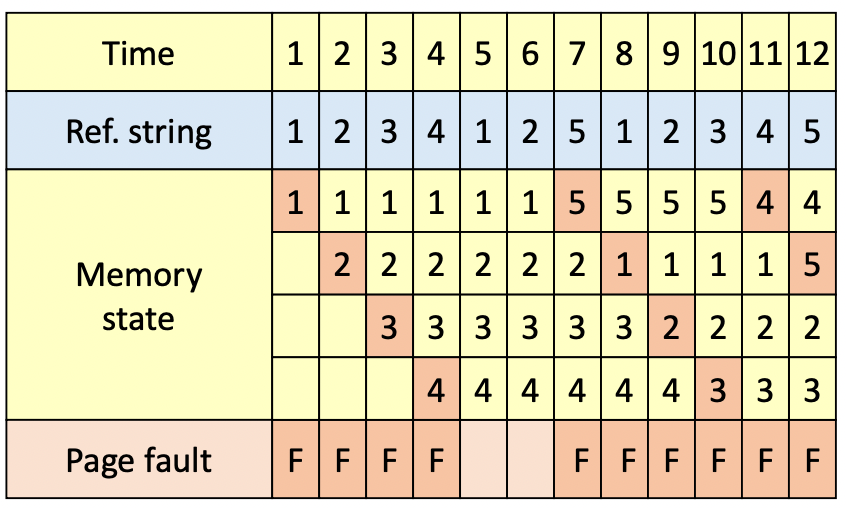
4. LRU(Least Recently Used) algorithm
- 가장 오랫동안 참조되지 않은 page를 교체
- Locality에 기반을 둔 교체 기법
- MIN algorithm에 근접한 성능을 보유
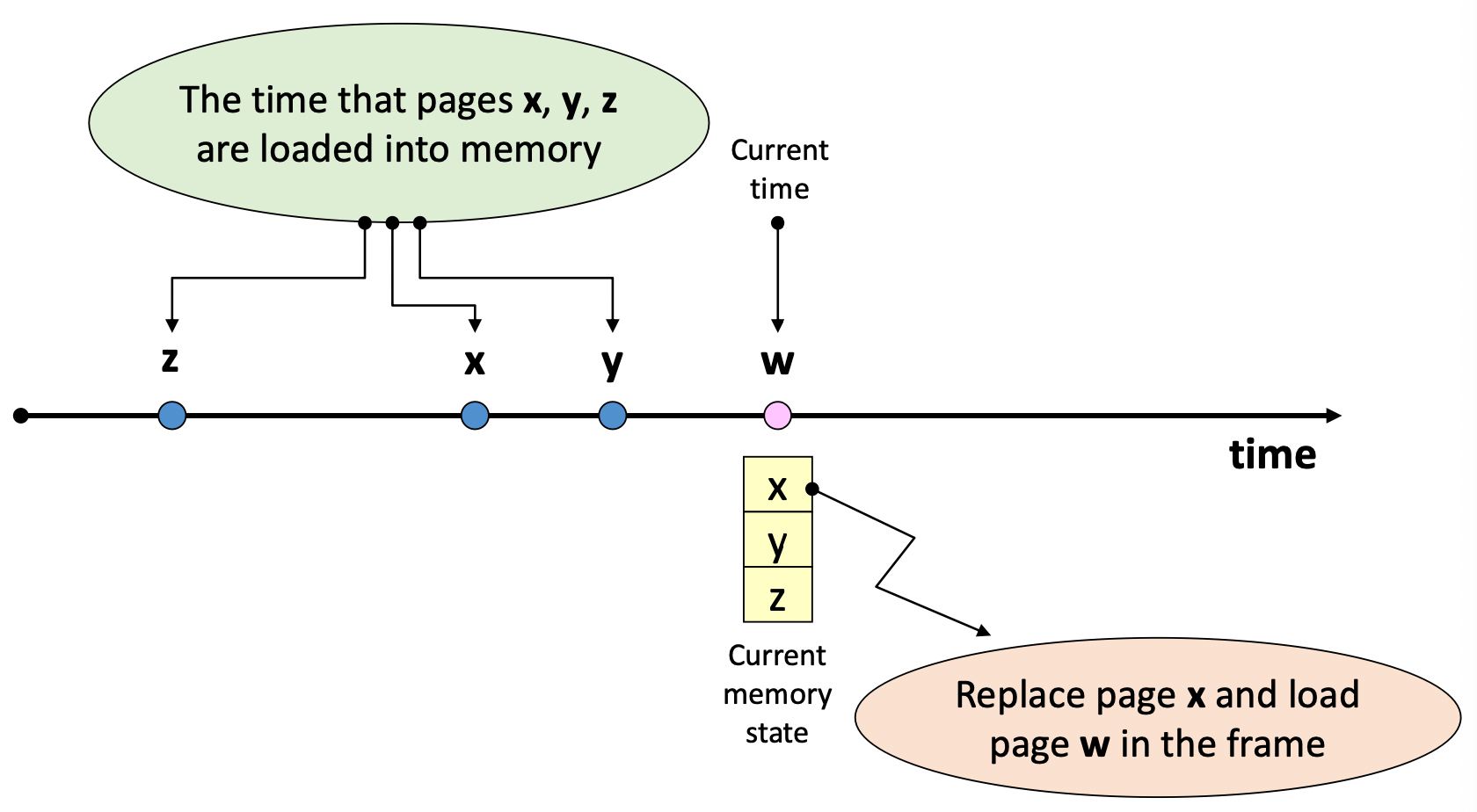
- 단점
- 참조 시 마다 시간을 기록해야 함 → Overhead↑
- loop 실행에 필요한 크기보다 작은 수의 Page frame이 할당되면, page fault수가 급격히 증가함
5. LFU(Least Frequently Used) algorithm
- 가장 참조 횟수가 적은 Page를 교체
- locality를 활용 → LRU 대비 적은 overhead
- 단점
- 최근 적재된, 참조될 가능성이 높은 page가 교체 될 가능성이 있음


6. NUR(Not Used Recently) algorithm
- Bit vector를 사용하여 LRU 알고리즘과 비슷한 성능을 달성
- Reference bit vector(r), Update bit vector(m)
- 교체 순서
- (r, m) = (0, 0)
- (r, m) = (0, 1)
- (r, m) = (1, 0)
- (r, m) = (1, 1)

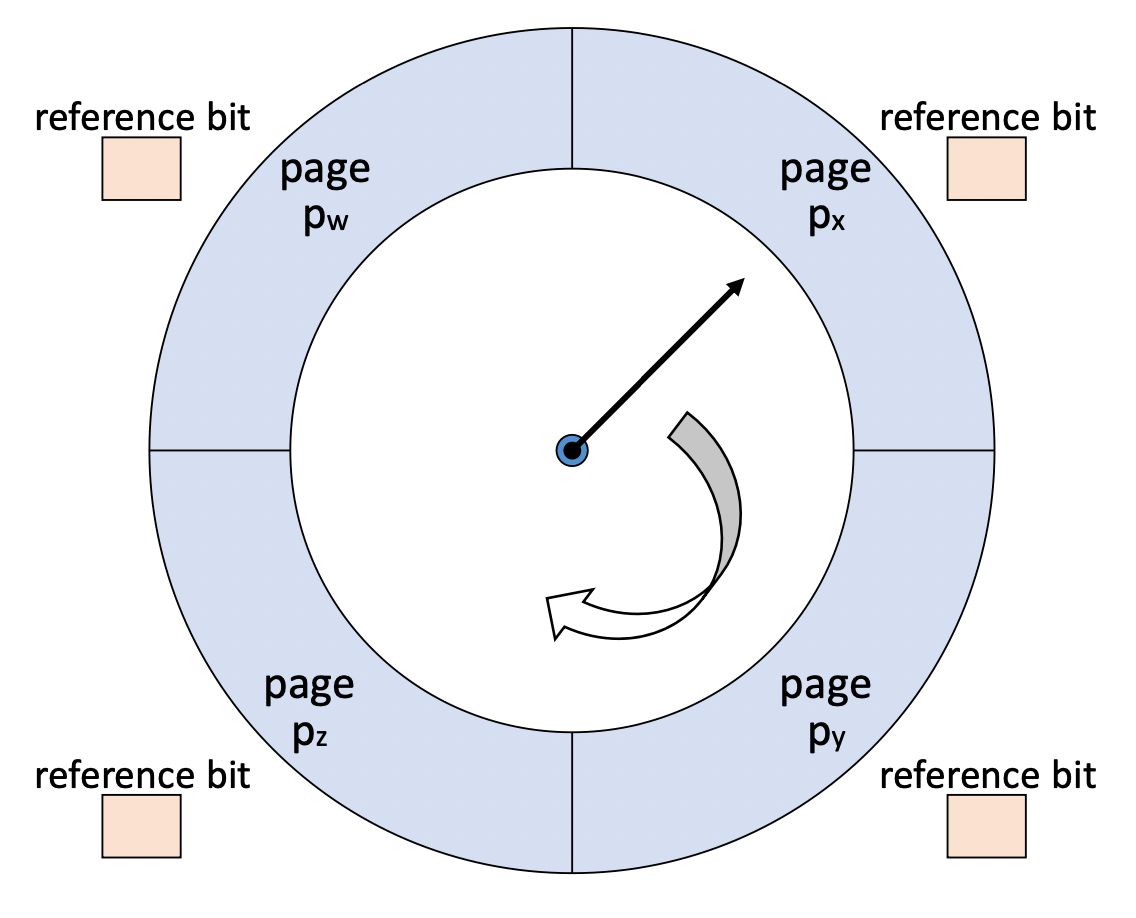
7. Clock algorithm
- Reference bit을 사용 → 주기적인 초기화 없음
- page frame들을 순차적으로 가리키는 pointer를 사용하여 교체될 Page를 결정
- reference bit = 0이면 교체될 page로 결정
- reference bit = 1이면 0으로 초기화 후 다음 page로 pointer를 이동 시킴
- page frame들을 순차적으로 가리키는 pointer를 사용하여 교체될 Page를 결정
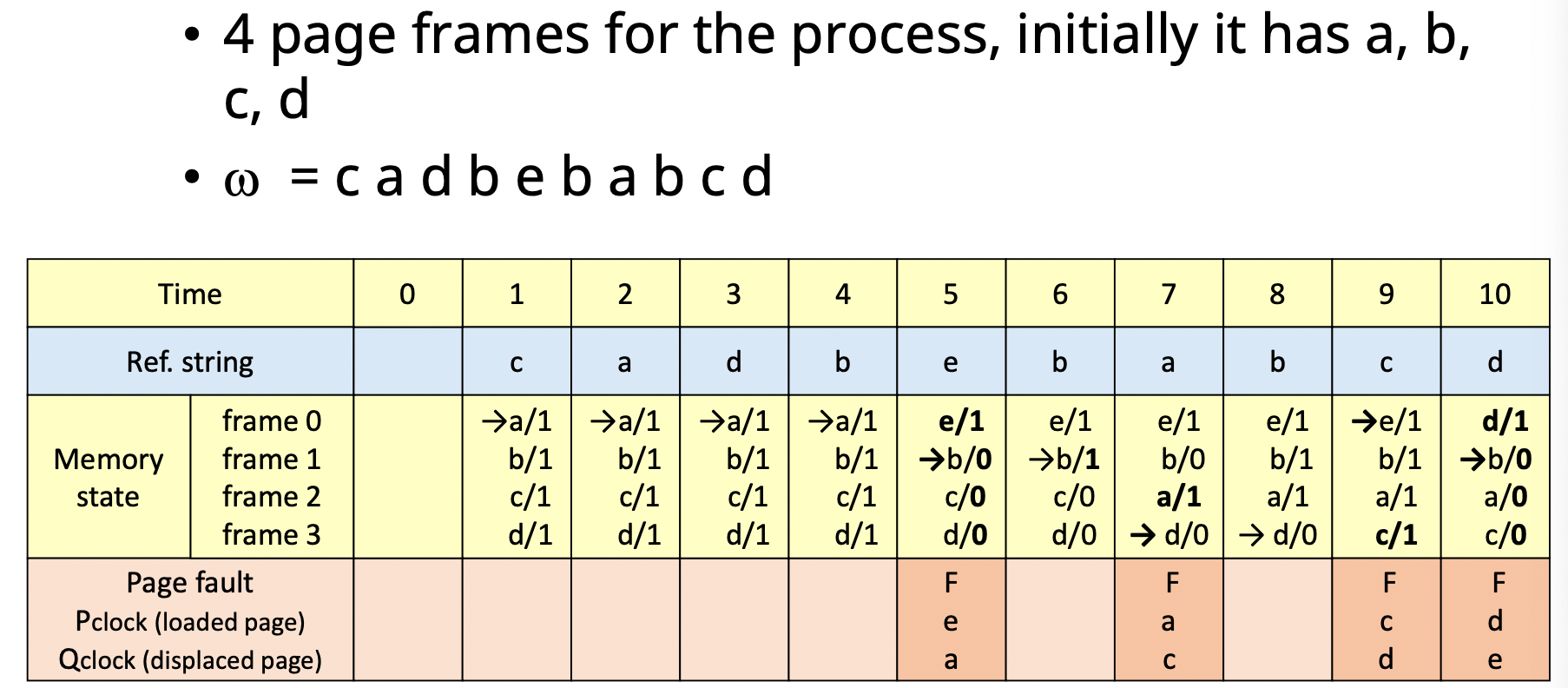
8. Second chance algorithm
- clock algorithm과 유사한 방법
- update bit(m)도 함께 고려 함.
- 현재 가리키고 있는 Page의 (r, m) 확인
- (0, 0) : 교체 page로 설정
- (0, 1) : (0, 0)으로 변경, write-back list에 추가 후 이동
- (1, 0) : (0, 0)로 변경 후 이동
- (1, 1) : (0, 1)로 변경 후 이동
-

5.2 Variable allocation을 위한 교체 기법
1. VMIN algorithm
- $[t, t+\Delta]$를 고려하여 교체할 page 선택
- page가 t시간에 참조 되면, (𝑡, 𝑡 + ∆]사이에 다시 참조되는지 확인하여 참조가 안되면 메모리에서 해당 page를 내린다.
- 최적의 알고리즘
- 하지만 실현이 불가능함
- 최적 성능을 위한 $\Delta=\frac{R}{U}$
- R : page fault 발생 시 처리 비용
- U : 한번의 참조 시간 동안 page를 메모리에 유지하는 비용
2. WS algorithm
- Working Set
- process가 특정 시점에 자주 참조하는 Page들의 집합
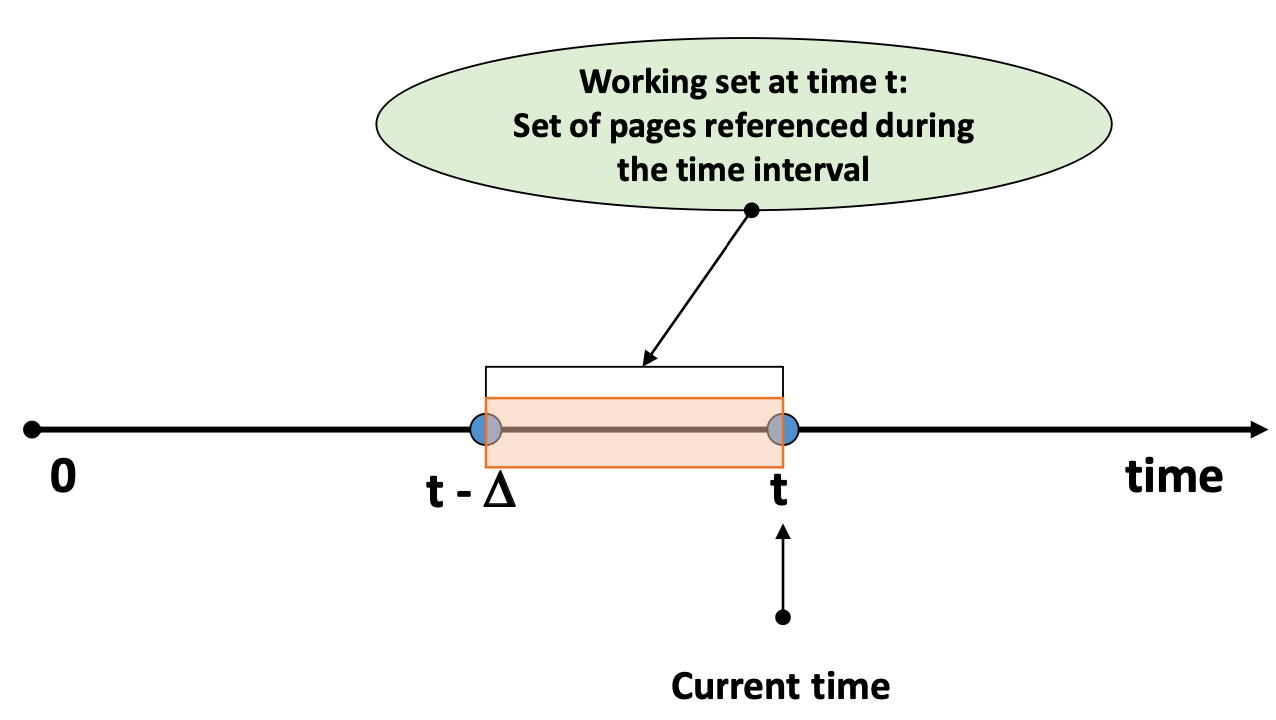
- 최근 일정시간 동안($\Delta$ : window size) 참조된 page들의 집합
- 시간에 따라 변화 함
- $W(t,\Delta)$
- $[t-\Delta, t]$ 동안 참조된 pages들의 집합
- locality에 기반을 둠
- Woring set을 메모리에 항상 유지 → thrashing↓
- Window size($\Delta$)는 고정, Memory allocation은 가변 → 서로 반대면 LRU
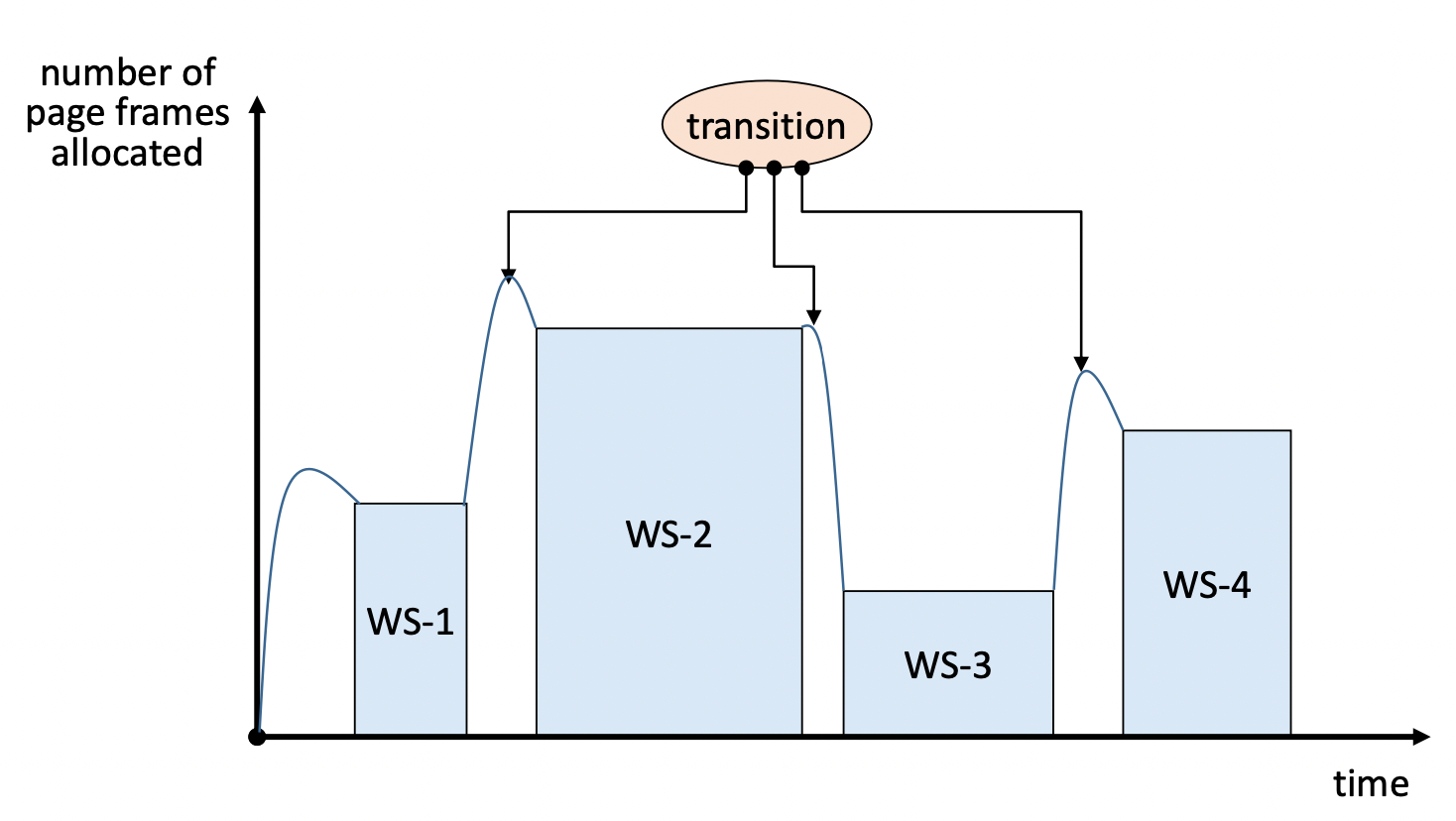
- Working set transition
- 성능 평가 : Page fault 수와 Page 유지비용도 함계 고려해야 함.
- 특징
- 적재 되는 page가 없더라도, 메모리를 반납하는 page가 있을 수 있음
- 새로 적재되는 page가 있을 더라도, 교체 되는 page가 없을 수 있음

3. PFF algorithm
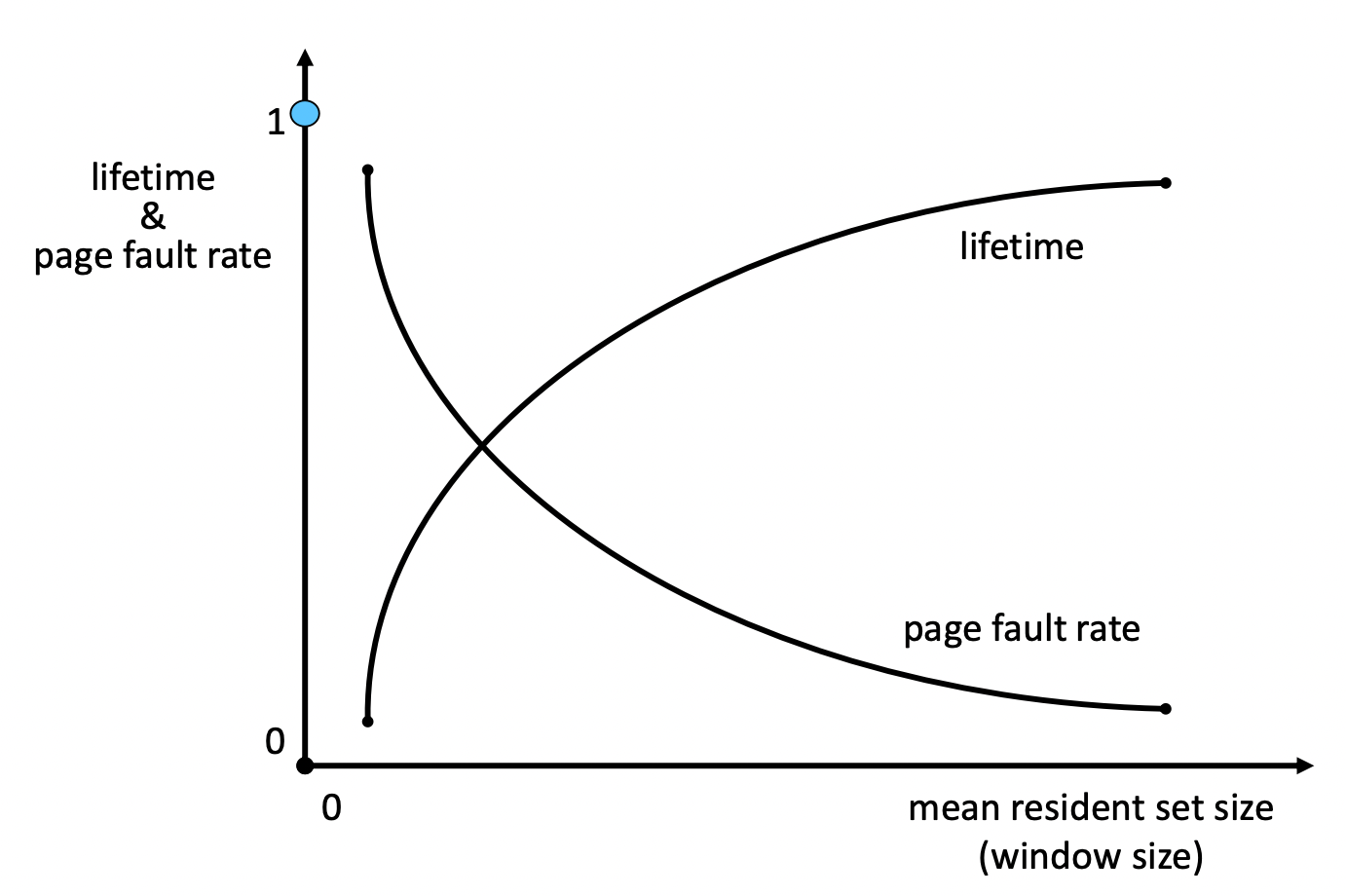
- Residence set size를 page fault rate에 따라 결정
- Low page fault rate → 할당된 page frame 감소
- High page fault rate → 할당된 page frame 증가
- page fault가 발생하면 residenct set 갱신 및 메모리 할당
- 기준 : $\tau$ (threshold value), IFT = 현재 page fault 시간 - 이전 page fault시간
- IFT > $\tau$ : Low page fault rate
- IFT < $\tau$ : HIgh page fault rate
6. Other considerations
- Page Size
-
Small page size Large page size page의 수 증가 감소 내부 단편화 감소 증가 I/O 시간 증가 감소 Locality 향상 저하 page fault 증가 감소 - 하드웨어가 발전함에 따라 점점 크기가 커지고 있음
- cpu의 발전속도가 disk의 발전속도보다 빠르기 때문에 병목현상이 올 수 있는데 이를 I/O 시간의 감소로 해결할 수 있기 때문
-
- TLB Reach
- TLB를 통해 접근 할 수 있는 메모리의 양
- (The number of entries) $\times$ (the page size)
'CS > [OS]' 카테고리의 다른 글
| Chapter12 입출력 시스템 & 디스크 관리 (0) | 2022.01.06 |
|---|---|
| Chapter11 파일 시스템 (0) | 2022.01.04 |
| Chapter9 가상메모리 (0) | 2021.12.28 |
| Chapter8 메모리(주기억장치) 관리 (0) | 2021.12.23 |
| Chapter7 교착상태(Deadlock Resolution) (0) | 2021.12.21 |